
Megan – Year 13 Student
Editor’s Note: This essay forms part of a collection of student works published in the 2020 edition of Salutaris, the GSAL Sixth Form academic journal. This is the first time that this piece of work has been published online. CPD
There are three kinds of lies: lies, damned lies, and statistics.
(Unknown, 1885)
Statistics are a popular and widely used tool within media and science, usually used to empahsise or evidence a point. However, statistics can be misused, and manipulated to overemphasise a point, or used as a scare tactic; nowhere is this more prevalent than within pharmaceutical journals and advertisements. How many advertisements for a drug or treatment have you seen with a headline promising a dramatic improvement, with a seemingly huge percentage of the test group seeing improved results while using that treatment? However, the statistics have been manipulated to show this, and the actual results can sometimes be drastically different. But how do companies do this?
One of the major tactics used by these companies to overemphasise their results is the publishing of relative results, rather than absolute results. For example, considering a hypothetical study performed on a drug that is hypothesised to prevent headaches: 2.2% of the test group that receives a placebo, or no drug, experiences headaches, compared to 1% of the test group that received the drug. If this result were published as an absolute reduction, there is only a 1.2% reduction in the people experiencing headaches when receiving the drug, compared to a placebo. However, this result can be manipulated to exaggerate the benefit by presenting as a 56% reduction in headaches (i.e. 1.2% reduction divided by the 2.2% of participants with headaches in the treatment group). This value is seemingly much more impressive, indicative of a much more effective drug, and likely to boost sales more than the absolute reduction value, so is favoured by the company.
Another of the tactics frequently used by these companies, particularly when tracking the effects of their treatment or drug over several years are graphs, and in particular the manipulation of the scales and the axis of the graphs they choose to display. Study the following graphs, Graph A and Graph B.
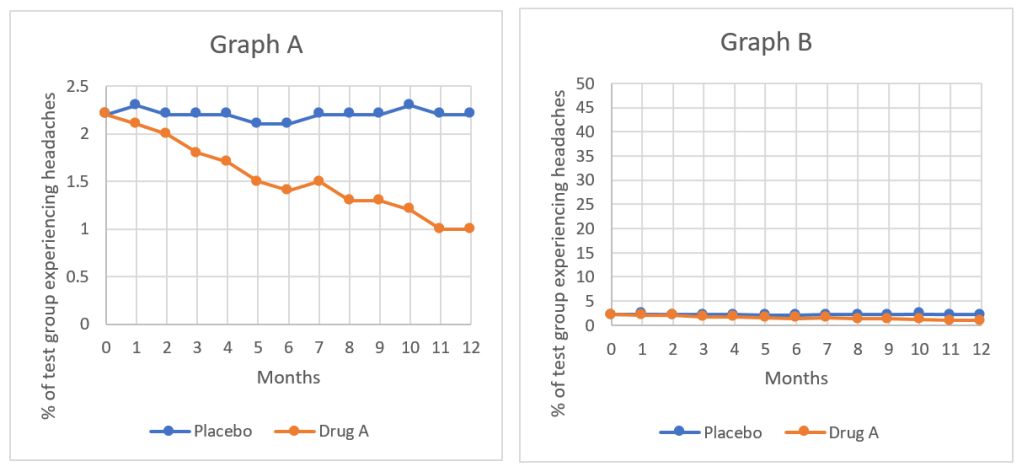
Graphs A and B show the results of the earlier study on the drug used to prevent headaches, the two graphs show the exact same results, with the same monthly values used to plot each. The difference between the two graphs is the scale used on the vertical axis, the percentage of the test group experiencing headaches; this difference causes the results seemingly shown by graph A to look much more impressive. The scale used for graph A is much smaller, meaning that the difference between the trendline for the group receiving the placebo and the group receiving the drug occupies over half the page, compared to graph B, where the scale used is much larger, and there is barely a difference between the two trend lines. From these graphs it would seem that the drug used for graph A is much more effective than the drug used in graph B; however, they are the same drug and the same results, just plotted using different scales.
Another way these graphs are used to maximise the effects of the smallest difference is through data manipulation. Study the following graphs, Graph Study the following graphs, Graph A and Graph C and Graph A again.

Graph C again shows exactly the same results as both graph A and graph B; however the data used to plot graph C has been manipulated so that graph C shows the natural log of the two variables plotted against each other, and because of this, seemingly shows a much larger difference in the results of the two test groups, a seemingly much more effective drug, even though exactly the same results have been plotted.
The third tactic commonly used by drug companies is the breakdown and misrepresentation of probabilities. Let us consider a test that is administered to pregnant women, to test for Down’s syndrome in the foetus. Approximately 1% of babies that are born have Down’s syndrome, meaning that 99% of babies born do not. When the test is administered, if the baby has Down’s syndrome, there is a 90% chance that the test will show a positive result. However, if the baby does not have Down’s syndrome, there is still a 1% chance that the result shown by the test will be positive. This can be represented by the following probability tree diagram.

Let us then consider the following situation: A woman takes the test, and receives a positive result, what is the probability that her baby has Down’s syndrome? From the probabilities given above, this test is seemingly fairly rigorous, giving the correct result a very large proportion of the time; it would therefore be reasonable to assume the probability of the baby having Down’s syndrome following a positive test to be large, perhaps estimated at >90%.
Let us calculate the actual probability: A positive result can consist of 90% chance that it is a true positive, or 1% chance that it is a false positive result. In order to calculate the probability of the baby having Down’s syndrome following a positive test, we need to divide the probability that the test is positive and the baby has Down’s syndrome, by the total probability of a positive test.
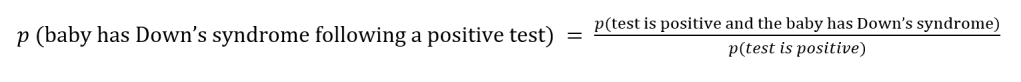
The probability that a test is positive and the baby has Down’s syndrome, is shown by the branch of the following probability tree diagram (highlighted in orange), and can thus be calculated as: 0.01 x 0.90 = 0.009.
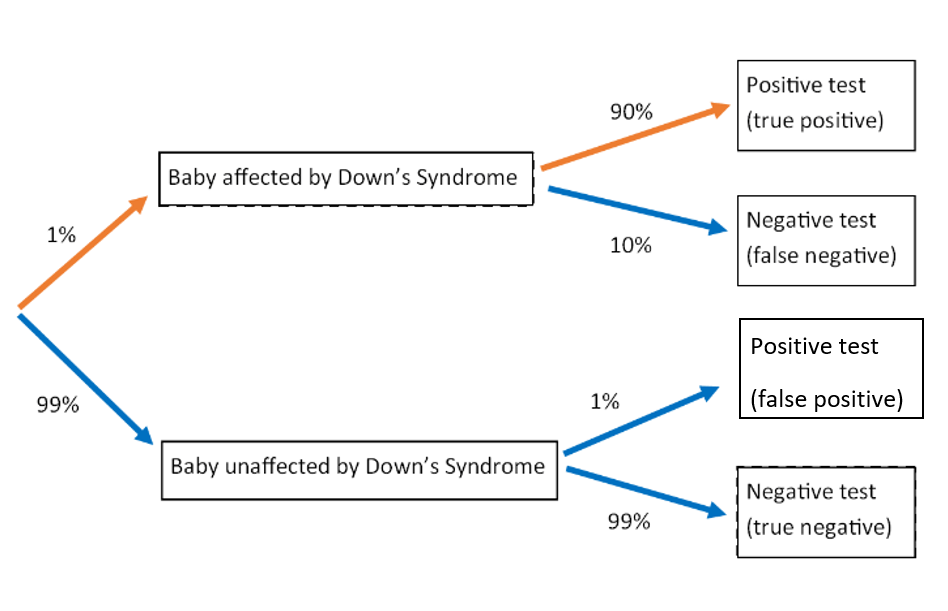
The probability of a positive test (shown by the green boxes in the following probability tree diagram), either a false positive or true positive, can be calculated by the addition of the two branches highlighted in the following probability tree diagram (both the red path and the orange path show positive test outcomes), and can thus be calculated as: Orange path = 0.01 x 0.90 = 0.009. Red path = 0.99 x 0.01 = 0.0099. Total = 0.009 + 0.0099 = 0.0189 (both the green boxes).

Using these values to then calculate the probability of the baby having Down’s syndrome following a positive test gives us the equation:
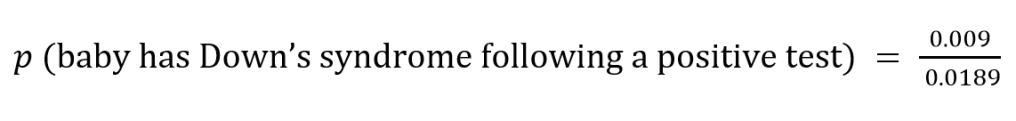
This gives us a value of 0.476, or 47.6%; this means that following a positive test, it is actually more probable that the baby will not have Down’s syndrome than that the baby will have Down’s syndrome, the complete opposite of what would be expected from the first glace at the initial percentages.
So what can be gathered from all this? While statistics are an invaluable tool for displaying and interpreting data, and often play a crucial part in scientific evidence, they are very vulnerable to misuse, but also misinterpretation. While it ought to be the responsibility of the company, or the scientific group to ensure that the statistics they are publishing are as clear and easy to correctly interpret by the layman as possible, this will almost never be the case as manipulation of statistical results can lead to lucrative profits. This means that it is vitally important that you, as the consumer or reader, are aware of these tricks that are used and are therefore able to see past them, and better use your own judgement to draw conclusions.

One thought on “How to Lie with Statistics”